On learning associations of faces and voices
Publication
Asian Conference on Computer Vision
Authors
Changil Kim, Hijung Valentina Shin,Tae-Hyun Oh, Alexandre Kaspar, Mohamed Elgharib, Wojciech Matusik
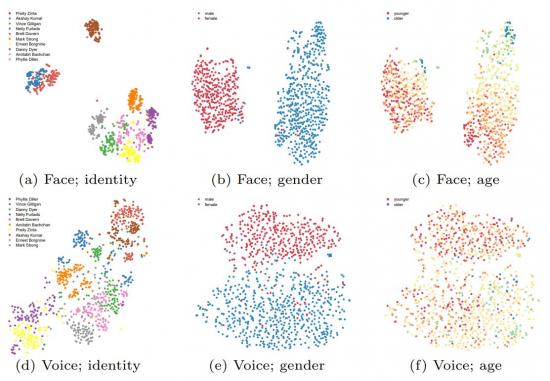
Abstract
In this paper, we study the associations between human faces and voices. Audiovisual integration, specifically the integration of facial and vocal information is a well-researched area in neuroscience. It is shown that the overlapping information between the two modalities plays a significant role in perceptual tasks such as speaker identification. Through an online study on a new dataset we created, we confirm previous findings that people can associate unseen faces with corresponding voices and vice versa with greater than chance accuracy. We computationally model the overlapping information between faces and voices and show that the learned cross-modal representation contains enough information to identify matching faces and voices with performance similar to that of humans. Our representation exhibits correlations to certain demographic attributes and features obtained from either visual or aural modality alone. We release our dataset of audiovisual recordings and demographic annotations of people reading out short text used in our studies.