Data-Efficient Graph Grammar Learning for Molecular Generation
Publication
ICLR
Authors
Minghao Guo, Veronika Thost, Beichen Li, Payel Das, Jie Chen, Wojciech Matusik
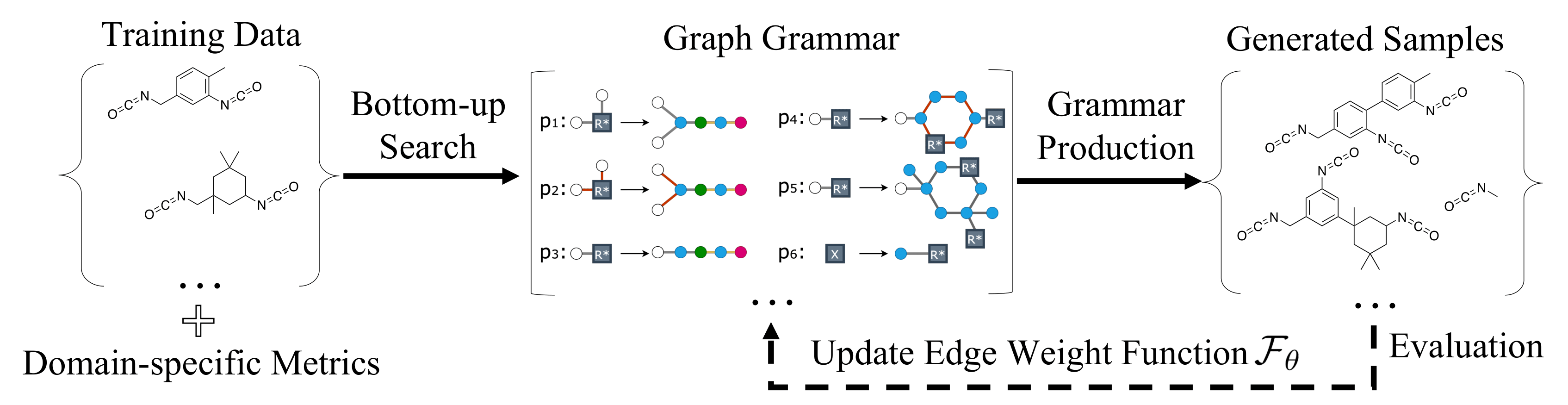
Abstract
The problem of molecular generation has received significant attention recently. Existing methods are typically based on deep neural networks and require training on large datasets with tens of thousands of samples. In practice, however, the size of class-specific chemical datasets is usually limited (e.g., dozens of samples) due to labor-intensive experimentation and data collection. This presents a considerable challenge for the deep learning generative models to comprehensively describe the molecular design space. Another major challenge is to generate only physically synthesizable molecules. This is a non-trivial task for neural network-based generative models since the relevant chemical knowledge can only be extracted and generalized from the limited training data. In this work, we propose a data-efficient generative model that can be learned from datasets with orders of magnitude smaller sizes than common benchmarks. At the heart of this method is a learnable graph grammar that generates molecules from a sequence of production rules. Without any human assistance, these production rules are automatically constructed from training data. Furthermore, additional chemical knowledge can be incorporated in the model by further grammar optimization. Our learned graph grammar yields state-of-the-art results on generating high-quality molecules for three monomer datasets that contain only ∼20 samples each. Our approach also achieves remarkable performance in a challenging polymer generation task with only 117 training samples and is competitive against existing methods using 81k data points.